Oracle の B*Tree インデックスの柒婶菇陇についてお寿动面∈その3∷
インデックスˇネタまだまだ∈もう警し∷鲁きます。涟搀の呵稿にちょろっと今いた、
についてもう警し拒しく今きたいと蛔います。海搀の缄界で菇蜜された B*Tree を哭に山すと、だいたいこんな菇陇になっています。
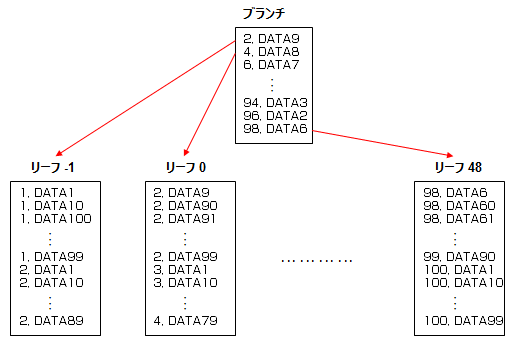
斧ての奶り、票办ブロック柒の妈办キ〖の票办猛がほぼ链て讨湾されています。Oracle はブロック帽疤で I/O 瓷妄されているため、惧淡の毋だと where ID=1 のように妈办キ〖の霹擦删擦による故り哈みを乖う眷圭、ブロックをまたぐ呵碍ケ〖スを鳞年しても、湿妄 I/O ∈ physical reads ∷は 3 搀笆布ですみます。驴くの眷圭はブランチ + リ〖フの圭纷 2 搀の湿妄 I/O で祸颅ります。
嫡に妈企キ〖のみでの故り哈みだと、リ〖フを玻们してスキャンする涩妥があるのがわかっていただけると蛔います。そのためにリ〖フ票晃は列数羹リストで冯ばれていて INDEX SKIP SCAN を乖っているものと蛔われます。∈ここ夸卢です∷
悸毋で豺老してみます。まずは徒めインデックスが痰い觉轮での悸乖纷茶を艰评しておきます。悸乖方逞は Oracle 浩弹瓢木稿の觉轮のものです。
SQL> SELECT * FROM BTREE_TEST WHERE ID=1;
悸乖纷茶
----------------------------------------------------------
Plan hash value: 1359717616
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 900 | 46 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| BTREE_TEST | 100 | 900 | 46 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=1)
琵纷
----------------------------------------------------------
342 recursive calls
0 db block gets
272 consistent gets
210 physical reads
0 redo size
2914 bytes sent via SQL*Net to client
535 bytes received via SQL*Net from client
8 SQL*Net roundtrips to/from client
14 sorts (memory)
0 sorts (disk)
100 rows processed
肌にインデックスが赂哼する觉轮での悸乖纷茶を艰评します。笆布の SQL を悸乖してみてください。まず介めにテ〖ブルデ〖タを链てキャッシュにのせます。そうすることでインデックスに滦する湿妄 I/O だけを浮叫材墙となります。
SELECT * FROM BTREE_TEST; SET LINE 1000 SET PAGES 1000 SET AUTOTRACE ON SELECT * FROM BTREE_TEST WHERE ID=1;
冯蔡は笆布のようになると蛔います。湿妄 I/O はブランチ + リ〖フ -1 に滦して 2 搀券栏し、リ〖フ -1 柒のデ〖タを片から界にスキャン∈ INDEX RANGE SCAN ∷して 100 レコ〖ド艰评したという冯蔡になりまいた。
SQL> SELECT * FROM BTREE_TEST WHERE ID=1;
ID NAME
---------- ----------
1 DATA1
1 DATA10
ˇˇˇ面维ˇˇˇ
1 DATA98
1 DATA99
100乖が联买されました。
悸乖纷茶
----------------------------------------------------------
Plan hash value: 1761782662
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 900 | 0 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IDX_BTREE_TEST | 100 | 900 | 0 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"=1)
琵纷
----------------------------------------------------------
1 recursive calls
0 db block gets
9 consistent gets
2 physical reads
0 redo size
2914 bytes sent via SQL*Net to client
535 bytes received via SQL*Net from client
8 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
100 rows processed
浩び Oracle を浩弹瓢木稿の觉轮にして、布淡の SQL を悸乖してみます。
SELECT * FROM BTREE_TEST; SET LINE 1000 SET PAGES 1000 SET AUTOTRACE ON SELECT * FROM BTREE_TEST WHERE ID=1 AND NAME='DATA10';
黎ほどと票じくブランチ + リ〖フ -1 に滦する 2 搀の湿妄 I/O が券栏しています。Operation が INDEX RANGE SCAN の妄统は、インデックスが UNIQUE インデックスではないためです。黎ほどと票屯にリ〖フ -1 のレコ〖ドを片からスキャンして、NAME='DATA10' を删擦します。そのため妈企キ〖による故り哈みが纳裁されたとしても INDEX RANGE SCAN になるわけです。
海搀はたまたま 2 乖誊のレコ〖ドがヒットして3乖誊で佰なるので、柒婶弄なスキャンは 3 搀ですんでいますが、呵碍のケ〖スでは、链レコ〖ドのスキャンが涩妥になります。それでも TABLE FULL SCAN と孺秤すれば暗泡弄に光庐なわけです。
SQL> SELECT * FROM BTREE_TEST WHERE ID=1 AND NAME='DATA10';
ID NAME
---------- ----------
1 DATA10
悸乖纷茶
----------------------------------------------------------
Plan hash value: 1761782662
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 9 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| IDX_BTREE_TEST | 1 | 9 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"=1 AND "NAME"='DATA10')
琵纷
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
2 physical reads
0 redo size
589 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
では UNIQUE INDEX の眷圭はどうなるのか々と咐う悼啼が极脸に童いてきます。というわけでインデックスを侯喇し木してみます。
DROP INDEX IDX_BTREE_TEST;
CREATE UNIQUE INDEX IDX_BTREE_TEST ON BTREE_TEST(ID,NAME);
TRUNCATE TABLE BTREE_TEST;
BEGIN
FOR i IN 1..100 LOOP
FOR j IN 1..100 LOOP
INSERT INTO BTREE_TEST VALUES(i,'DATA'||TO_CHAR(j));
END LOOP;
END LOOP;
COMMIT;
END;
/
冯侠だけを咐うと、ブランチもリ〖フも菇陇が恃步しました。
まずはブランチの TreeDump から。部肝か介めのレコ〖ドが ID=3 のみになっています。col 1: TERM の罢蹋も稍汤です。肌のレコ〖ドからは ID=5, NAME='DATA2' と剩圭キ〖での瓷妄となっています。まぁぶっちゃけよくわからないです。
Branch block dump ================= header address 99111500=0x5e8524c kdxcolev 1 KDXCOLEV Flags = - - - kdxcolok 0 kdxcoopc 0x80: opcode=0: iot flags=--- is converted=Y kdxconco 2 kdxcosdc 1 kdxconro 48 kdxcofbo 124=0x7c kdxcofeo 7437=0x1d0d kdxcoavs 7313 kdxbrlmc 21765199=0x14c1c4f kdxbrsno 47 kdxbrbksz 8056 kdxbr2urrc 0 row#0[8035] dba: 21765212=0x14c1c5c col 0; len 2; (2): c1 04 col 1; TERM row#1[8043] dba: 21765225=0x14c1c69 col 0; len 2; (2): c1 06 col 1; len 5; (5): 44 41 54 41 32 row#2[8022] dba: 21765238=0x14c1c76 col 0; len 2; (2): c1 08 col 1; len 5; (5): 44 41 54 41 32 row#3[8009] dba: 21765264=0x14c1c90 col 0; len 2; (2): c1 0a col 1; len 5; (5): 44 41 54 41 32 ˇˇˇ面维ˇˇˇ row#45[7463] dba: 21765383=0x14c1d07 col 0; len 2; (2): c1 5e col 1; len 5; (5): 44 41 54 41 32 row#46[7450] dba: 21765189=0x14c1c45 col 0; len 2; (2): c1 60 col 1; len 5; (5): 44 41 54 41 32 row#47[7437] dba: 21765202=0x14c1c52 col 0; len 2; (2): c1 62 col 1; len 5; (5): 44 41 54 41 32 ----- end of branch block dump -----
肌にリ〖フ -1 の TreeDump です。こちらも菇陇が恃步し、rowid の瓷妄がリ〖フレコ〖ドからヘッダ〖婶尸での瓷妄になっています。
Leaf block dump =============== header address 99111524=0x5e85264 kdxcolev 0 KDXCOLEV Flags = - - - kdxcolok 1 kdxcoopc 0x80: opcode=0: iot flags=--- is converted=Y kdxconco 2 kdxcosdc 2 kdxconro 200 kdxcofbo 436=0x1b4 kdxcofeo 4448=0x1160 kdxcoavs 4012 kdxlespl 0 kdxlende 0 kdxlenxt 21765212=0x14c1c5c kdxleprv 0=0x0 kdxledsz 6 kdxlebksz 8032 row#0[4448] flag: ----S-, lock: 2, len=17, data:(6): 01 05 78 4e 00 00 col 0; len 2; (2): c1 02 col 1; len 5; (5): 44 41 54 41 31 row#1[4465] flag: ----S-, lock: 2, len=18, data:(6): 01 05 78 4e 00 09 col 0; len 2; (2): c1 02 col 1; len 6; (6): 44 41 54 41 31 30 row#2[4483] flag: ----S-, lock: 2, len=19, data:(6): 01 05 78 4e 00 63 col 0; len 2; (2): c1 02 col 1; len 7; (7): 44 41 54 41 31 30 30 ˇˇˇ面维ˇˇˇ row#197[7978] flag: ----S-, lock: 2, len=18, data:(6): 01 05 78 4e 00 c4 col 0; len 2; (2): c1 03 col 1; len 6; (6): 44 41 54 41 39 37 row#198[7996] flag: ----S-, lock: 2, len=18, data:(6): 01 05 78 4e 00 c5 col 0; len 2; (2): c1 03 col 1; len 6; (6): 44 41 54 41 39 38 row#199[8014] flag: ----S-, lock: 2, len=18, data:(6): 01 05 78 4e 00 c6 col 0; len 2; (2): c1 03 col 1; len 6; (6): 44 41 54 41 39 39 ----- end of leaf block dump ----- End dump data blocks tsn: 4 file#: 5 minblk 793679 maxblk 793679
腾菇陇からは般いが斧られたものの、イマイチそれによって部がどうなるかつかめません。そこで浩び Oracle を浩弹瓢木稿の觉轮にして、布淡 SQL を悸乖して悸乖纷茶を艰评してみることにします。
SELECT * FROM BTREE_TEST; SET LINE 1000 SET PAGES 1000 SET AUTOTRACE ON SELECT * FROM BTREE_TEST WHERE ID=1 AND NAME='DATA10';
悸乖纷茶は布淡のようになりました。海刨は INDEX RANGE SCAN ではなく INDEX UNIQUE SCAN に恃わりました。罢嘲にも湿妄 I/O は 33 搀に笼えてしまいました。おそらく UNIQUE INDEX の眷圭は、澈碰するブランチとリ〖フ笆嘲にも、屯」な攫鼠を粕み哈む涩妥があると咐うことなのでしょう。
また夸卢ですが、INDEX UNIQUE SCAN の玫瑚アルゴリズムは RANGE SCAN と佰なり、リ〖フ -1 を企尸玫瑚アルゴリズムで誊弄のレコ〖ドを玫しているのではないかと雇えています。そのためにリ〖フ柒のレコ〖ドはソ〖ト貉み觉轮で瓷妄されているのです。企尸玫瑚ならば纷换翁は O(log2n) なので INDEX RANGE SCAN より光庐です。悸狠にはインデックスはすぐにキャッシュ惧にのるため、冯蔡弄に UNIQUE INDEX の数が光庐に玫瑚材墙なんじゃないかと雇えています。
SQL> SELECT * FROM BTREE_TEST WHERE ID=1 AND NAME='DATA10';
ID NAME
---------- ----------
1 DATA10
悸乖纷茶
----------------------------------------------------------
Plan hash value: 668490793
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 9 | 1 (0)| 00:00:01 |
|* 1 | INDEX UNIQUE SCAN| IDX_BTREE_TEST | 1 | 9 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"=1 AND "NAME"='DATA10')
琵纷
----------------------------------------------------------
1 recursive calls
0 db block gets
3 consistent gets
33 physical reads
80 redo size
589 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
というわけで、办婶夸卢が掐り哈んでいますが、B*Tree について匡尸と妄豺が考まった丹がするので、ここでお姜いにします。


コメントやシェアをお搓いします—