Oracle の B*Tree インデックスの内部構造についてお勉強中(その1)
お仕事のデータベース一式のリース切れ間近ということで、リース延長で耐えることができるのか、それともシステム更改が必要なのかを見極めるため、最近はデータベース周りのチューニングばかりやってます。
当初設計時に、5年間持つ設計をしたのですが、流石に5年目にもなると予定とはそれなりに乖離が発生するものです。テーブル&インデックス設計をユーザ向けの処理をとにかく高速に処理できるように設計したので、ユーザ向けの処理は速度的に全然大丈夫なのですが、データの肥大化によるバッチ処理のパフォーマンス劣化が顕著です。単純にストレージと CPU パワーが足りていないのでしょう。
しかしながらチューニングの余地はまだまだ十分にありそうです。バッチ向けの最適化を図ることにしました。うまくいけば来年度どころか、後数年はリース延長で延命できるかもしれません。
今回実施したチューニングの1つのポイントとして、バッチ処理向けのインデックスの最適化があげられます。結果的には、ユーザ向けの処理劣化なしにバッチ処理を10倍以上高速化できたバッチ処理もありました。
ずばり!複数キーによるインデックス、つまり複合索引(コンポジット索引)のキーの順序のチューニングが良く効きます!基本的に、第1キーで同じデータが同一ブロック内もしくは隣接するブロック内に存在する形になります。従って、複合キーのどのカラムを第1キーに持ってくるかをアプリケーションの要件と照らし合わせてよく考える必要があります。
なぜ近くのブロックに固まって存在するかを理解するためには Oracle のデフォルトのインデックス構造でもある B-Tree (正確には B*Tree)の構造を理解しておく必要があります。
Oracle のインデックス構造について、詳細に記載された資料はさすがに出回っていないので、TreeDump コマンドの内容と、B*Tree の一般的な構造から想定するに、Oarcle のインデックス構造は下記の図のような構造になっています。
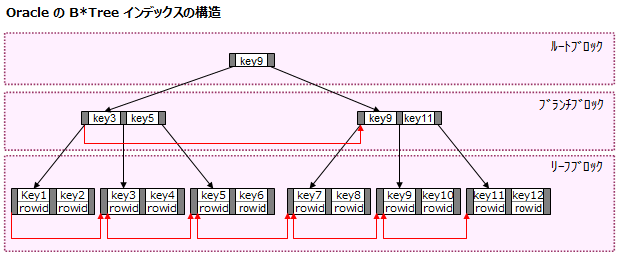
複合索引の場合の構造について、書籍やネットで情報を集めたのですが情報を得ることができませんでした。したがって、こちらも TreeDump のデータから想定するしかありません。僕の解析での結論は下記の通りです。
- リーフブロック以外のブロックでも、複合キー全ての情報を保持しています。B*Tree のアルゴリズムを拡張して、複数キーによる木構造を管理できるようにしていると思われます。※キーを何らかの文字列で1つの文字列にしたデータで管理しているのではありません。上記図で単純に key* と記載されている部分は、キーにしたカラム数分のデータと読み替えてください。
- リーフブロックでは、小さなテーブルのように複合キー全ての情報と ROWID をカラムとして保持しています。ただし、UNIQUE INDEX の場合は、ROWID 情報を各レコードのヘッダ部分で保持しています。
- 各リーフブロック間は、お互いのポインタ情報を双方向リストとして保持し、範囲検索、比較演算子等の処理の高速を実現しています。この構造は B*Tree というより B+Tree のはずなんだが・・・。
ちなみに、木構造は、B-Tree でも B+Tree でもなく、B*Tree を採用しているらしいのですが、TreeDump だけからは判別することはできませんでした。(判別する能力がありませんでした・・・とも言います。)
TreeDump での解析方法についての説明は次エントリで行うこととして、ここでは、B-Treeの各アルゴリズムについて整理をしておきたいと思います。以下 Wikipedia からの引用です。
B-Tree について
多分木の平衡木(バランス木)である。1 ノードから最大 m 個の枝が出るとき、これをオーダー m のB木という。後述する手順に従って操作すると、根と葉を除く「内部ノード」は最低でも m /2 の枝を持つことを保証できる。
各ノードは、枝の数 - 1 のキーを持つ。枝1 〜 枝m と キー1 〜 キーm -1 を持つとき、枝i には キーi -1 より大きく キーi より小さいキーだけを保持する(キーの重複を許す場合はどちらかに等号をつける)。
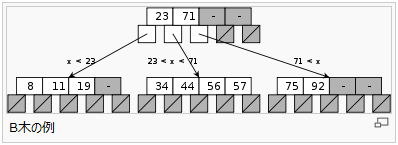
葉ノードの定義は文献によって違いが見られる。木の終端をヌルポインタのような特殊な値で表す場合、枝がすべて終端記号となっているノードを葉とする。これに対して一部の文献では、終端を表すためにキーが0個のノードを連結し、このノードを葉と定義している。すなわち、後者の定義における葉ノードの親が、前者の定義における葉ノードとなる。後者の定義をとる文献では「葉ノードはキーを持たない」ということになる。以下の記述では、前者の定義に従うものとする。
ノードはページと呼ばれることもある。特にハードディスクドライブなどの外部記憶装置を使ってB木を実現する場合によく見られる。この場合、各ノード(ページ)のサイズが、外部記憶装置のブロックサイズの整数倍になるようにオーダーを調整することが多い。
B木の中でも特に、オーダー3のものを2-3木、オーダー4のものを2-3-4木と呼ぶ。
B*Tree について
B*木(英: B*-tree)は、B木から派生した木構造の一種で、HFS や Reiser4 ファイルシステムで使われている。根ノード以外のノードは、B木のように1/2ではなく、2/3まで埋まった状態になる。このため、ノードがいっぱいになったとき即座に分割するのではなく、キーを次のノードと共有する。連続する2つのノードがいっぱいになると、それを3つのノードに分割する。また、常に左端のキーは使わずに残しておく。一般に総称して「B木」と呼ばれることが多く、「B*木」と呼ばれることは滅多にない。
B*木とB+木は異なる。後者は、葉ノードが連結されて連結リストを構成するようになっているものである。B+木は、挿入のコストを増大させて、検索を効率化したものである。
IEEE 0-8186-4212-2 1993 には B**木の定義も見られた[1]。
B+Tree について
B+木(英: B+ tree)は、キーを指定することで挿入・検索・削除が効率的に行える木構造の一種である。動的な階層型インデックスであり、各インデックスセグメント(「ブロック」などと呼ばれる。木構造におけるノードに相当)にはキー数の上限と下限がある。B+木はB木とは異なり、全てのレコードは木の最下層(葉ノード)に格納され、内部ノードにはキーのみが格納される。
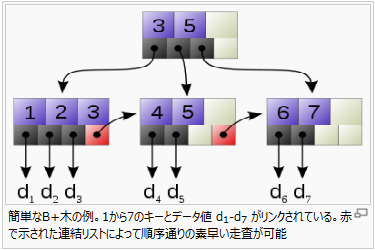
B+木は、特にブロック型記憶装置での効率的データ検索に効果を発揮する。ブロックサイズ b の記憶装置があるとき、b の倍数個のキーを格納するB+木は2分探索木に比較して非常に効率が良い(2分探索木はブロック型でない記憶装置に適している)。
ReiserFS(UNIX、Linux)、XFS(IRIX、Linux)、JFS2(AIX、OS/2、Linux)、HammerFS(DragonFly BSD)、NTFSといったファイルシステムはいずれもB+木に類する構造をブロックのインデックス付けに使っている。関係データベースでも表のインデックスにこの種の木構造を使っていることが多い。
HFS Plus Volume Format - Bツリー
せっかく調べてまとめていたので、HFS Plus Volume Format - Bツリーに関しても資料として残しておきます。
B*Tree についての実装の一例としては、前述したとおり、MacOS のボリュームフォーマット HFS Plus があげられます。Oracle の B*Tree とは構造が結構違います。まぁアルゴリズムのベースが B*Tree というだけで、それぞれの要件にあわせた実装を含むと、細部のデータ構造はそれなりに違うってことですね。
内部構造含めて、http://developer.apple.com/jp/technotes/tn1150.html にかなり詳細に解説されています。いくつか重要ポイントだけ、解説ページから引用したいと思います。
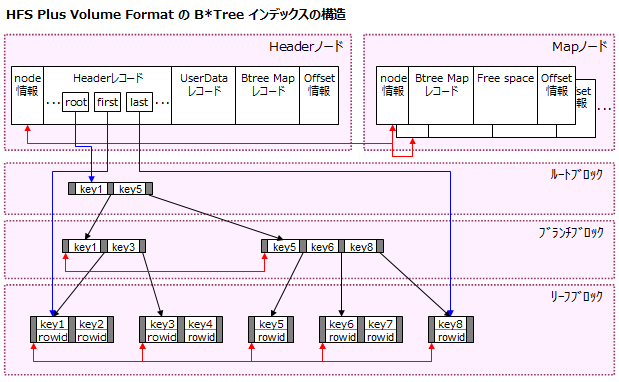
HFS Plus Volume Format B*Tree には下記の 4 種類のノードがあります。
- それぞれの B ツリーには 1 つのヘッダーノードが含まれています。ヘッダーノードは常に B ツリー内の先頭ノードです。このノードには、ツリー内の他のノードを検索するときに必要な情報が含まれています。
- マップノードにはマップレコードが含まれます。マップレコードには、ヘッダーノードのマップレコードに収まりきらないアロケーションデータ(B ツリー内の空きノードを示すビットマップ)が格納されます。
- インデックスノードには B ツリーの構造を定義するポインタレコードが含まれます。keyLength、キー、およびノード番号が含まれます。ポインタレコードで指定された番号を持つノードは、インデックスノードの子ノードと呼ばれます。1 つのインデックスノードは、ノードのサイズとノードに含まれるキーのサイズによって、2 つまたはそれ以上の子ノードを持ちます。
- リーフノードには、キーに関連付けられているデータを含むデータレコードが格納されます。(このノードには、ポインタレコードの代わりにデータレコードが含まれます。)各データレコードに対応するキーは一意でなければなりません。データレコードには、keyLength、キー、およびキーに関連付けられたデータが含まれます。
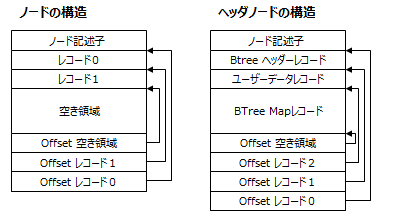
ノードの内部構造に関する説明
- ノード記述子には、ノードに関する基本的な情報と、他のノードとの相互リンクが含まれます。
- それぞれのレコードは、ノードの末尾にあるレコードのオフセットのリストを使ってアクセスされます。
ヘッダノードの内図構造に関する説明
- ヘッダーレコードには、B ツリーのサイズ、最大のキー長、先頭および最後のリーフノードの位置など、B ツリーに関する一般的な情報が含まれています。
- ユーザデータレコードには、B ツリーにかかわる情報を格納することができます。必ず 128 バイトの長さがあります。
- マップレコードには、B ツリー内のどのノードが使用されていて、どのノードが使用されていないかを示すビットマップ情報が含まれています。
ってことで、事前の B-Tree に関するお勉強はココまで。次エントリでは Oracle のインデックスをダンプする TreeDump コマンドの使い方と、実際のインデックスの内部構造の考察について記載します。


コメントやシェアをお願いします!