JIS X 0213:2004(JIS2004) で本当に文字化けする文字
前回「Vista で導入される JIS X 0213:2004(JIS2004) のまとめ(お勉強編)」という記事を書きましたが、本当に文字化けする文字について調査しました。僕は Perl 使いなので検証は Perl のみです。
今回の文字化けの定義は、
SJIS - EUC - UTF8 を相互変換する過程において元の文字コードに戻したときに元のコードに戻ってこない文字を文字化けする
とします。Perl で文字コードを操作する方法は、Encode.pm と旧Jcode.pm (0.8系)がメジャーどころなので、その2つについて調査しました。Encode.pm に関しては、Encode::JP と Encode::JIS2K を対象としました。
- スポンサーリンク -
まず結論から。Encode::JIS2K を使う限り、文字化けする SJIS コードは以下の35文字です。
- JIS2004 で追加された10文字:879F 889E 9873 989E EAA5 EFF8 EFF9 EFFA EFFB EFFC
- カ行に半濁音(゜)を付けた文字など一部の文字: 82f5 82f6 82f7 82f8 82f9 8397 8398 8399 839a 839b 839c 839d 839e 83f6 8663 8667 8668 8669 866a 866b 866c 866d 866e 8685 8686
わかりやすく図に直すと、赤色の部分が文字化けする文字です。(※通常絶対使わない文字と思います)
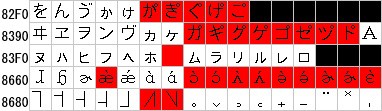
- Encode::JIS2K で SIS -> UTF8 -> SJIS と SJIS -> EUC -> SJIS で元のコードに戻るか?
- Encode::JP で SJIS -> UTF8 -> SJIS と SJIS -> EUC -> SJIS で元のコードに戻るか?
- Jcode で SJIS -> UTF8 -> SJIS と SJIS -> EUC -> SJIS で元のコードに戻るか?
- Encode::JIS2K で SIS -> EUC -> UTF8 -> EUC と SJIS -> UTF8 -> EUC -> UTF8 で EUC -> EUC と UTF8 -> UTF8 に注目して元のコードに戻るか?
さすがに手作業は無理なのでプログラム作って比較してます。
use strict;
use warnings;
use Encode::JIS2K;
use Encode qw/encode decode from_to/;
use Jcode;
my %null;
while (my $data = <DATA>) {
$data=~s/[\x01-\x1b]//g;
$null{$_} = 1 foreach(split ',', $data);
}
check1('sjis_utf_sjis_encodejis2k.txt', 'shiftjisx0213', 'utf8');
check1('sjis_euc_sjis_encodejis2k.txt', 'shiftjisx0213', 'euc-jisx0213');
check1('sjis_utf_sjis_encode.txt', 'shiftjis', 'utf8');
check1('sjis_euc_sjis_encode.txt', 'shiftjis', 'euc-jp');
check1('sjis_utf_sjis_jcode.txt', 'sjis', 'utf8');
check1('sjis_euc_sjis_jcode.txt', 'sjis', 'euc');
check2('sjis_euc_utf_euc_encodejis2k.txt', 'shiftjisx0213', 'euc-jisx0213', 'utf8');
check2('sjis_utf_euc_utf_encodejis2k.txt', 'shiftjisx0213', 'utf8', 'euc-jisx0213');
sub check1 {
my $file = shift;
my $code_src = shift;
my $code_dst = shift;
open my $fh, ">$file" or die 'file error';
print $fh ("$code_src -> $code_dst -> $code_src\n");
foreach my $i (0x8140..0x8FFF, 0x9040..0x9FFF, 0xE040..0xEFFF, 0xF040..0xFCFF) {
my $hexi = sprintf("%x",$i);
next if( ($i & 0xFF) < 0x40 ||
($i & 0xFF) == 0x7f ||
($i & 0xFF) >= 0xfd && ($i & 0xFF) <= 0xff ||
exists $null{$hexi}
);
my $sjis = pack("C2" ,$i >> 8, $i & 0xFF);
my $enc = $sjis;
($file !~ /jcode/) ? from_to($enc, $code_src, $code_dst)
: Jcode::convert(\$enc, $code_dst, $code_src);
my $dec = $enc;
($file !~ /jcode/) ? from_to($dec, $code_dst, $code_src)
: Jcode::convert(\$dec, $code_src, $code_dst);
if($sjis ne $dec) {
printf $fh ("%x -> %s -> %s\n", $i, unpack('H*', $enc), unpack('H*', $dec));
}
}
close $fh;
}
sub check2 {
my $file = shift;
my $code_src = shift;
my $code_dst1= shift;
my $code_dst2= shift;
open my $fh, ">$file" or die 'file error';
print $fh ("$code_src -> $code_dst1 -> $code_dst2 -> $code_dst1\n");
foreach my $i (0x8140..0x8FFF, 0x9040..0x9FFF, 0xE040..0xEFFF, 0xF040..0xFCFF) {
my $hexi = sprintf("%x",$i);
next if( ($i & 0xFF) < 0x40 ||
($i & 0xFF) == 0x7f ||
($i & 0xFF) >= 0xfd && ($i & 0xFF) <= 0xff ||
exists $null{$hexi}
);
my $sjis = pack("C2" ,$i >> 8, $i & 0xFF);
my $enc1 = $sjis;
from_to($enc1, $code_src, $code_dst1);
my $enc2 = $enc1;
from_to($enc2, $code_dst1, $code_dst2);
my $dec = $enc2;
from_to($dec, $code_dst2, $code_dst1);
if($enc1 ne $dec) {
printf $fh ("%x -> %s -> %s -> %s\n", $i, unpack('H*', $enc1), unpack('H*', $enc2), unpack('H*', $dec));
}
}
close $fh;
}
1;
__DATA__
82fa,82fb,82fc,84dd,84de,84df,84e0,84e1,84e2,84e3,84e4,84fb,84fc,86f2,86f3,86f4,86f5,86f6,86f7,86f8,86f9,86fa,8777,8778,8779,877a,877b,877c,877d,8790,8791,8792,8794,8795,8796,8797,879a,879b,879c,fcf5,fcf6,fcf7,fcf8,fcf9,fcfa,fcfb,fcfc
ってことで、今後は Encode::JP や旧Jcode.pm じゃなくて Encode::JIS2K を使いましょうってことですかね?あ、Jcode や Encode::JP で文字化けするコードはスクリプトを実行して結果を見て下さいね。
※Encode::JIS2K をすでに使ってるよって方、是非にご意見下さいませ。。。m(_ _)m
ちなみに、Encode::JIS2K を JIS2004 に対応させるのも10文字分の対応表を追加するだけなので自分用にちゃちゃっと作っちゃう分には比較的楽かもしれません。
- スポンサーリンク -


コメントやシェアをお願いします!
安達
!!は!が2つですが、‼はunicode1文字です。U+203Cです。
Encode::JIS2K;でもだめなようですが。