memcached で SERVER_ERROR out of memory storing object というエラ〖
ちょっと涟にエントリにも今いた度坛アプリですが、セッション瓷妄に repcached を蝗っています。repcached とは memcached にデ〖タのレプリケ〖ション怠墙を纳裁悸刘したもので KLab 臭及柴家が倡券したソフトウェアです。レプリケ〖ションの怠墙により材脱拉は若迢弄に羹惧しているかわりに、まぁぶっちゃけ庐刨はかなり稻婪になっています。ⅷベンチマ〖クをとったわけではないけど砷操テストで挛炊できるくらい般う。
さて、海搀のアプリケ〖ションサ〖バの菇喇としては、Oracle RAC + memcached でオラクルでも谗努なセッション瓷妄を— で今いたような笆布の菇喇になっています。
memcached のメモリには 1GB を充り碰てていたのですが、ちょっとメモリが警なかったようです。笨脱し幌めて眶泣稿にセッションが瘦积されない稍恶圭にみまわれました。匡疥に warn を慌哈んでトレ〖スしてみると、どうやら memcached が笆布のエラ〖を徘いている滔屯。
蛔いがけず memcached のソ〖スを粕むことになりました。
冯侠からするとメモリ稍颅のようです。しかもこの祸据は稿揭しますが repcached 泼铜のものであることも澄千しました。memcached-1.2.6-repcached-2.2 のソ〖スコ〖ドで咐うと、memcached.c 1532 乖誊の婶尸でのエラ〖です。
static void process_update_command(conn *c, token_t *tokens, const size_t ntokens, int comm, bool handle_cas) {
char *key;
size_t nkey;
×面维×
it = item_alloc(key, nkey, flags, realtime(exptime), vlen+2);
if (it == 0) {
if (! item_size_ok(nkey, flags, vlen + 2))
out_string(c, "SERVER_ERROR object too large for cache");
else
out_string(c, "SERVER_ERROR out of memory storing object");
/* swallow the data line */
c->write_and_go = conn_swallow;
c->sbytes = vlen + 2;
×面维×
票ロジックのメモリ稍颅のもう办つのエラ〖 SERVER_ERROR object too large for cache に簇しては笆涟もちょっと的侠になったことがあったようで、この收が徊雇になりました。
- のみまくし泣淡 - memcachedで糠しくキャッシュを瘦赂できないの泛
- のみまくし泣淡 - 鲁ˇmemcachedで糠しくキャッシュを瘦赂できないの泛
- memcached で糠しくキャッシュを瘦赂叫丸ない々— - にぽたん甫垫疥
- きのうの memcached ネタ - にぽたん甫垫疥
- memcached - Bulknews::Subtech - subtech
まぁ冯蔡をいうと、惧淡の稍恶圭はすでに memcached 娄で猖帘されていて链く侍の稍恶圭だったわけなんですけど、テストスクリプトは徊雇にさせて暮きました。
片が碍いので窗链に纳い磊れなかったんですけど、repcached の眷圭、ある泼年の掘凤で LRU による item の豺庶ができないみたいです。item.c の 124 乖誊×あたりのヤツ。ロジックとしては呵も概いデ〖タから界に玫瑚し、介めに叫附した徊救フラグなしの item を豺庶、呵络50改さかのぼっても豺庶できない眷圭はメモリ稍颅エラ〖とするって婶尸です。
item *do_item_alloc(char *key, const size_t nkey, const int flags, const rel_time_t exptime, const int nbytes) {
uint8_t nsuffix;
item *it;
char suffix[40];
size_t ntotal = item_make_header(nkey + 1, flags, nbytes, suffix, &nsuffix);
unsigned int id = slabs_clsid(ntotal);
if (id == 0)
return 0;
it = slabs_alloc(ntotal, id);
if (it == 0) {
int tries = 50;
item *search;
/* If requested to not push old items out of cache when memory runs out,
* we're out of luck at this point...
*/
if (settings.evict_to_free == 0) {
itemstats[id].outofmemory++;
return NULL;
}
/*
* try to get one off the right LRU
* don't necessariuly unlink the tail because it may be locked: refcount>0
* search up from tail an item with refcount==0 and unlink it; give up after 50
* tries
*/
if (tails[id] == 0) {
itemstats[id].outofmemory++;
return NULL;
}
for (search = tails[id]; tries > 0 && search != NULL; tries--, search=search->prev) {
if (search->refcount == 0) {
if (search->exptime == 0 || search->exptime > current_time) {
itemstats[id].evicted++;
STATS_LOCK();
stats.evictions++;
STATS_UNLOCK();
#ifdef USE_REPLICATION
replication_call_del(ITEM_key(search), search->nkey);
#endif /* USE_REPLICATION */
}
do_item_unlink(search);
break;
}
}
it = slabs_alloc(ntotal, id);
if (it == 0) {
itemstats[id].outofmemory++;
return NULL;
}
}
assert(it->slabs_clsid == 0);
it->slabs_clsid = id;
assert(it != heads[it->slabs_clsid]);
it->next = it->prev = it->h_next = 0;
it->refcount = 1; /* the caller will have a reference */
DEBUG_REFCNT(it, '*');
it->it_flags = 0;
it->nkey = nkey;
it->nbytes = nbytes;
strcpy(ITEM_key(it), key);
it->exptime = exptime;
memcpy(ITEM_suffix(it), suffix, (size_t)nsuffix);
it->nsuffix = nsuffix;
return it;
}
なんだかエントリが墓くなってきて、今くのが辱れてきましたが磋磨ります。浩附コ〖ドはこちら。呈羌するデ〖タサイズを 1.3 擒していくことで memcached に糠たな Slab を澄瘦するように动いるコ〖ドです。メモリ稍颅で alloc できなくなったところで SEVER_ERROR が券栏するはず。
192.168.0.1 / 192.168.0.2 の2骆に repcached をインスト〖ルしている菇喇でお活しを。
use strict;
use Cache::Memcached;
my $size = $ARGV[0] || 200000;
my $count = $ARGV[1] || 10;
my $expire = $ARGV[2] || 2;
my $cache = Cache::Memcached->new({
#servers => [ "192.168.0.1:10000" ],
#servers => [ "192.168.0.2:10000" ],
servers => [ "192.168.0.1:10000" , "192.168.0.2:10000" ],
debug => 0,
});
# XXX get immediately after storing
my $time = time;
print "store test\n";
for my $key ( 0 .. $count ) {
$key = "$time$key";
$cache->set( $key => "." x $size, $expire );
my $stored = $cache->get($key);
$size = $size * 1.3;
}
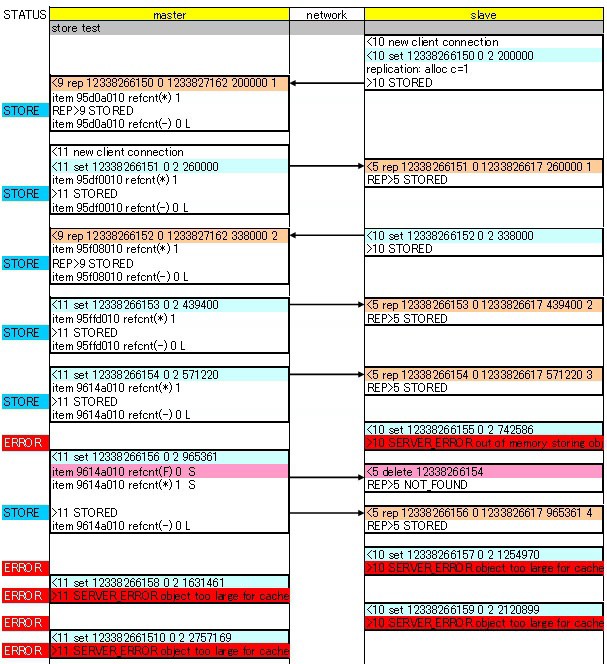
浮沮その1∷ master + slave 菇喇 ⅷこのケ〖スで稍恶圭が券栏する
[192.168.0.2]/usr/local/bin/memcached-debug -vv -d -m 1 -u memcache -l 192.168.0.2 -p 10000 -x 192.168.0.1 -v
memcached をデバッグモ〖ドで悸乖させておき、テストスクリプトを悸乖した狠に叫蜗されるデバッグメッセ〖ジを腊妨するとこんな炊じになります。
SERVER_ERROR out of memory storing object が叫蜗されています。
浮沮その2∷ master のみ弹瓢の菇喇 ⅷ♂帽挛の memcached
テストスクリプトは servers => [ "192.168.0.1:10000" ] で悸乖
この冯蔡が塑丸の memcached の瓢侯。メモリ稍颅でこれ笆惧 Slab が侯喇できないというエラ〖が叫蜗されます。

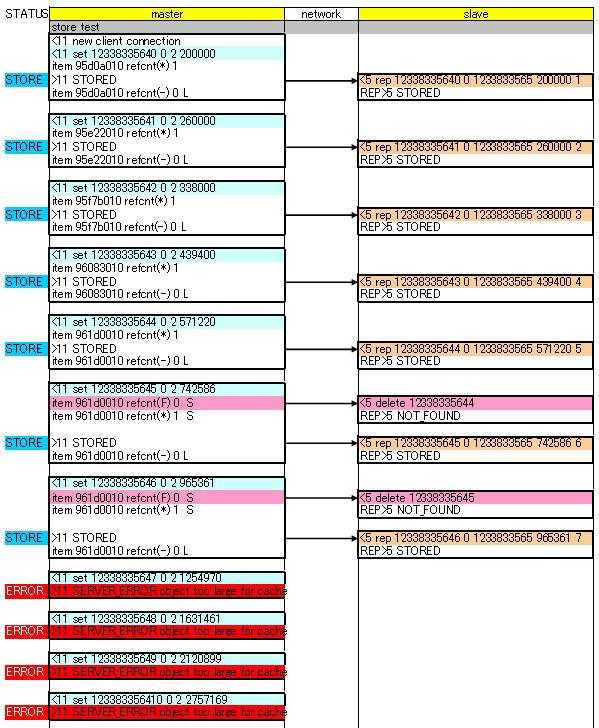
浮沮その3∷ master + slave 菇喇 ⅷmasterのみに儡鲁するパタ〖ン
[192.168.0.2]/usr/local/bin/memcached-debug -vv -d -m 1 -u memcache -l 192.168.0.2 -p 10000 -x 192.168.0.1 -v
テストスクリプトは servers => [ "192.168.0.1:10000" ] で悸乖
冯蔡は浮沮2と票じで、般いは master でデ〖タを STORED した狠に REP コマンドで slave へデ〖タが流られる爬のみ。
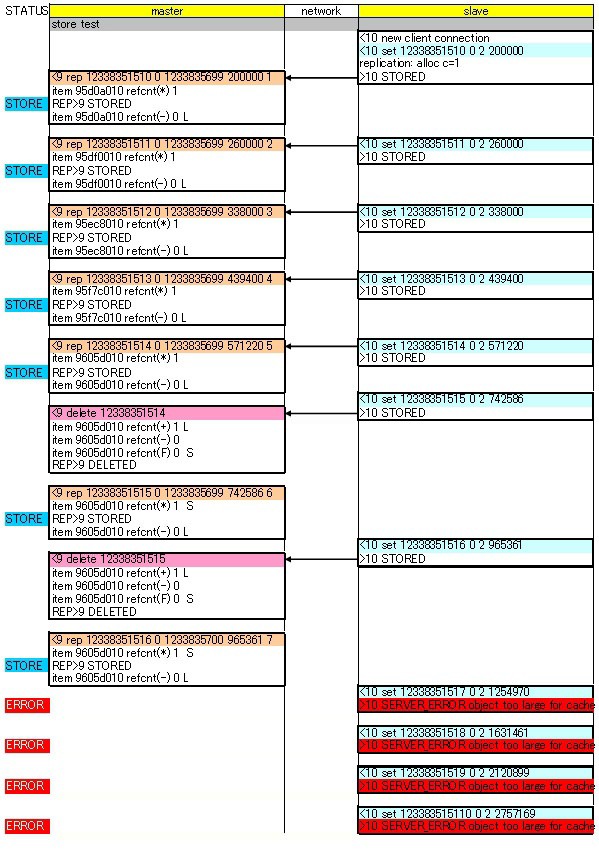
浮沮その4∷ master + slave 菇喇 ⅷslaveのみに儡鲁するパタ〖ン
[192.168.0.2]/usr/local/bin/memcached-debug -vv -d -m 1 -u memcache -l 192.168.0.2 -p 10000 -x 192.168.0.1 -v
テストスクリプトは servers => [ "192.168.0.2:10000" ] で悸乖
こちらは笺闯シ〖ケンスは恃わるものの、冯蔡弄には浮沮2と票じ冯蔡。LRU によるメモリ豺庶は master で瓷妄されているっぽく、master で delete コマンドを券乖させ、REP DELETE で slave 娄のデ〖タも猴近しています。鄂きができたらやっと STORED 觉轮になると。ⅷ笺闯哭が粗般えてるけどˇˇˇまぁいいや。
で、冯渡、なんで浮沮1の眷圭のみで介めの SERVER_ERROR が券栏するのか、プログラムを纳い磊れませんでしたが、キャッシュの expire を没くし、充り碰てるメモリを 1.5GB 镍にして、碰澈エラ〖が券栏しないようにアプリケ〖ション娄での拇腊で慰いでいます。塑碰は patch を今くところまでプログラムを纳い磊れれば紊かったのですが、蜗吭きてしまいましたˇˇˇ(^^《
というわけで、冯蔡弄には海のところ谗拇に瓢いています。w


コメントやシェアをお搓いします—